The Method
The goal of this post is to succinctly explain the main concepts used in the sample size computation method that powerly is based on. In doing so, I aim to help get you acquainted with terminology used throughout the rest of the posts in the tutorial section. You may regard this post as a summary of the key things discussed in Constantin et al. (2023).
Input
To start the search for the optimal sample size, powerly requires three inputs, namely, a true model, a performance measure, and a statistic.
True Model
The true model represents the set of hypothesized parameter values (i.e., the effect size) used to generate data during the first step of the method. These true parameter values are collected in a model matrix denoted . One may either manually specify or generate it according to some hyperparameters via the generate_model function. The meaning and function of changes depending on context in which it is used. For example, in the context of psychological networks, encodes the edge weights matrix, where the entries may represent partial correlation coefficients. However, in the Structural Equation Modeling (SEM), for example, may encode the model implied covariance matrix.
Performance Measure
The performance measure can be regraded as a quality of the estimation procedure relevant for the research question at hand. It takes the form of a function , where the argument is the matrix of true model parameters and is the matrix of estimated model parameters. In essence, the performance measure is a scalar value computed by comparing the two sets of model parameters in and . Together with the performance measure, the researcher also needs to specify a target value indicating the desired value for the performance measure. Therefore, what constitutes an optimal sample size largely depends on what performance measure the researcher is interested in, which, in turn, is driven by the research question at hand.
Statistic
The statistic is conceptualized as a definition for power that captures how the target value for the performance measure should be reached. It takes the form of a function , where the argument is vector of performance measures of size indexed by , with each element representing a replicated performance measure computed for a particular sample size.
Most commonly, this statistic may be defined in terms of the probability of observing a target value for the performance measure (i.e., analogous to a power computation) as:
where the notation represents the Iverson brackets (Knuth, 1992), with defined to be if the statement is true and otherwise. Therefore, the optimal sample size needs to satisfy , where is an arbitrary threshold indicating a certain probability of interest, i.e., the target value for the statistic.
Question
Taken together, the true model matrix , the performance measure with its corresponding target value , and the statistic with its target value allow one to formulate the following question:
Given the hypothesized parameters in , what sample size does one need to observe with probability as defined by ?
powerly strives for flexibility, allowing researchers to provide custom implementations for performance measures and statistics that best suit their study goals. However, it also provides out of the box support for several models and common related performance measures. Check out the Reference Section for the powerly function for an overview of the currently supported models and performance measures.
TIP
Coming in powerly version 2.0.0 we are introducing an API that allows researchers to build upon and easily extend the current method to new models and performance measures. Check out the Developer Section for updates on the API design and examples on how to extend powerly.
Steps
Given the inputs presented above, the search for the optimal sample size is conducted in three steps, i.e., a Monte Carlo (MC) simulation step for computing the performance measure and statistic at various sample sizes, a curve-fitting step for interpolating the statistic, and a bootstrapping step to quantify the uncertainty around the fitted curve.
Step 1
The goal of the first step is to get a rough understanding of how the performance measure changes as a function of sample size.
To achieve this we perform several MC simulations for different sample sizes selected from a candidate sample size range denoted , for example, . More specifically, we select indexed by equidistant samples as . Then, for each , we perform MC replications as follows:
- Generate data with number of observations using the true model parameters in .
- Estimate the model parameters matrix using the generated data.
- Compute the performance measure by applying function .
This procedure gives us an matrix , where each entry is a performance measure computed for the -th sample size, during the -th MC replication. Each column of the matrix is, therefore, a vector that holds the replicated performance measures associated with the -th sample size (i.e., see the plot below).
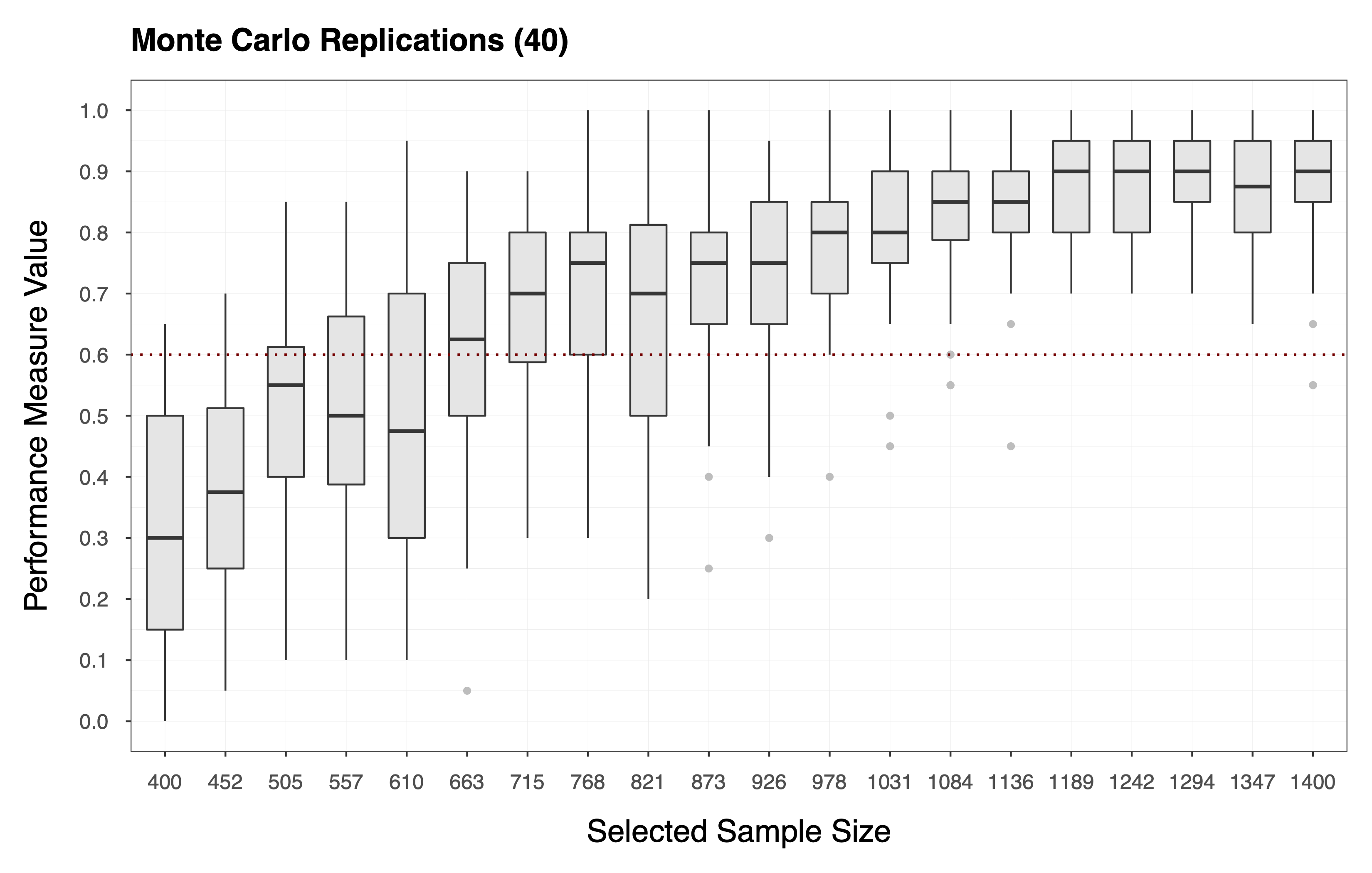
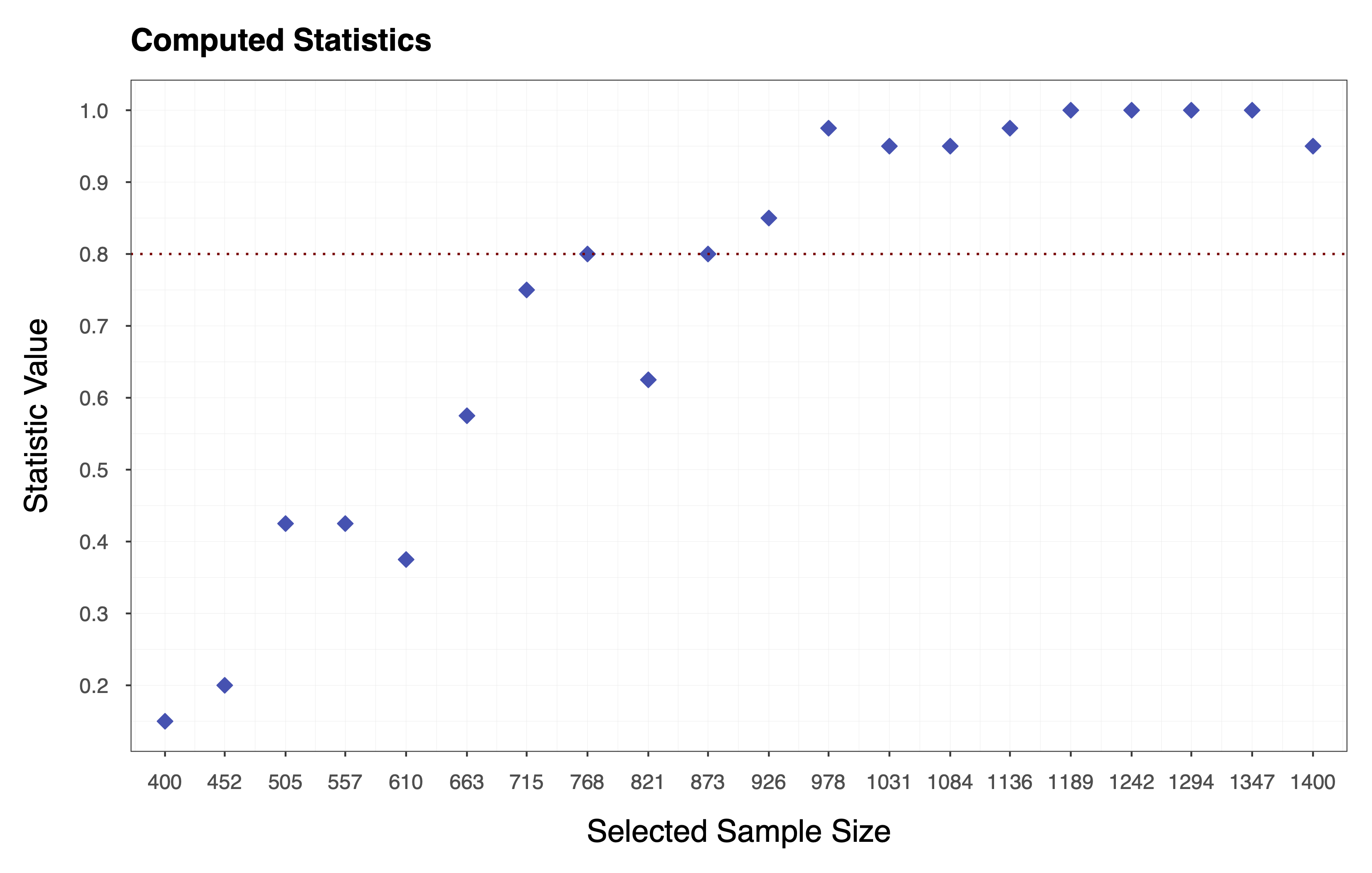
Finally, we compute the statistic of choice (e.g., Equation ) by applying the function to each column of the matrix of performance measures . In essence, we collapse the matrix to a vector of statistics . The plot below shows the statistics computed according to Equation , where each diamond represents the probability of observing a performance measure value . We can see that the target value for the statistic is, in this case, .
Step 2
The goal of the second step is to obtain a smooth power function and interpolate the statistic across all sample sizes in the candidate range .
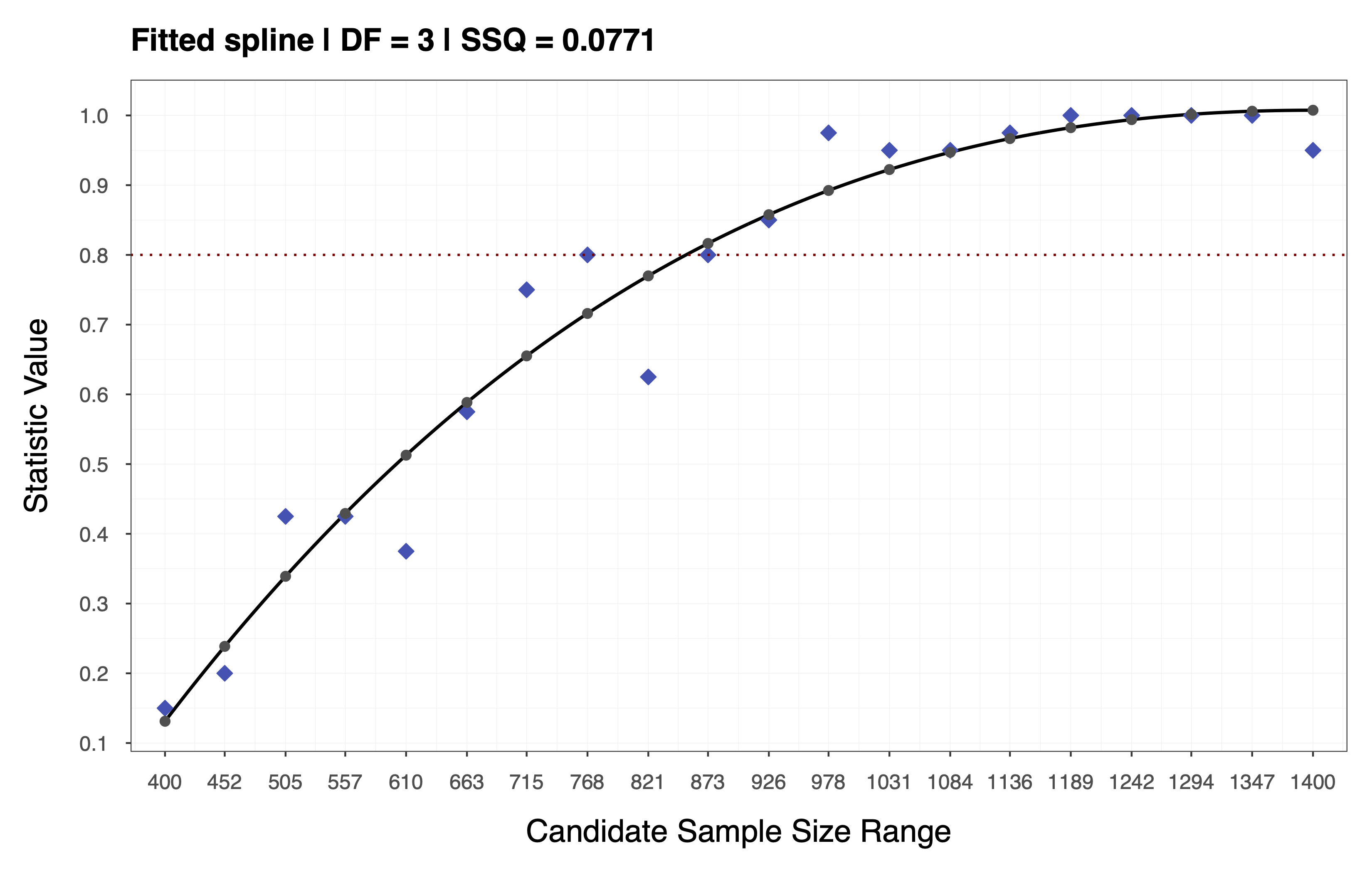
To achieve this, we fit a spline to the statistic values obtain in the previous step and use the resulting spline coefficients to interpolate across the entire range . Depending on the choice of performance measure and statistic, it may be appropriate to impose monotonicity constraints when fitting the spline. For the example above, we assume a monotone non-decreasing trend and use cubic I-Splines (de Leeuw, 2017; Ramsay, 1988) via the R package splines2 (Wang & Yan, 2021) with the number of inner knots selected based on a cross-validation procedure (e.g., leave-one-out). This assumption implies that the statistic increases as a function of sample size, as depicted in the plot below.
TIP
More information about the second step (i.e., basis functions, spline coefficients, and information about the cross-validation) can be obtained by running plot(results, step = 2), where the results object represents the output provided by the powerly function).
Step 3
The goal of the third step is to quantify the Monte Carlo error around the estimated spline.
To achieve this, we use nonparametric bootstrapping to capture the variability in the replicated performance measures associated with each sample size . More specifically, we perform bootstraps runs, with the index indicating the current bootstrap run, as follows:
- Efficiently emulate the MC procedure in Step 1 by sampling with replacement elements from each vector containing the replicated performance measures for the sample size .
- Compute a bootstrapped version of the vector of statistics , as discussed in Step 1 (i.e., see the animation below).
- Repeat the spline fitting procedure in Step 2, using as input the the bootstrapped vector of statistics instead of . Then, use the resulting bootstrapped spline coefficients to interpolate across the entire range .
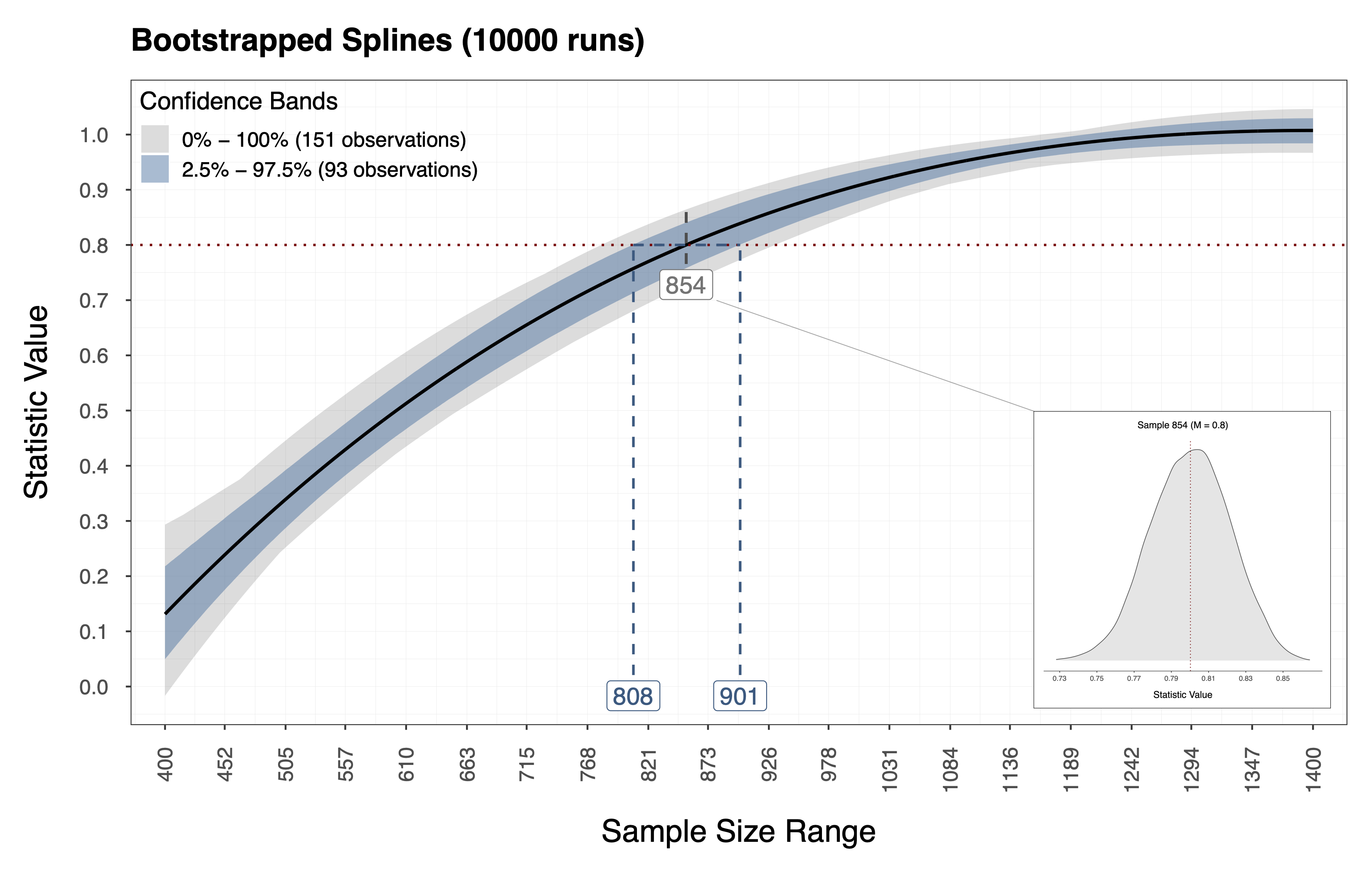
Performing the procedure above gives us a bootstrap distribution of statistic values for each sample size in the candidate range . In addition, we obtain this information using relatively few computational resources since we resample the performance measures directly and thus bypass the model estimation and data generation steps. Therefore, using this information we can compute Confidence Intervals (CI) around the observed spline we fit in Step 2. The plot below shows the observed spline (i.e, the thick dark line) and the resulting CI (i.e., the gray and blue bands) for the example above. Furthermore, the distribution depicted below shows the bootstrapped statics associated with a sample size (i.e., in this case).
Iterations
At this point, we can decide whether subsequent method iterations are needed by zooming in on intersection of the CI and the target value for the statistic (i.e., see the plot below).
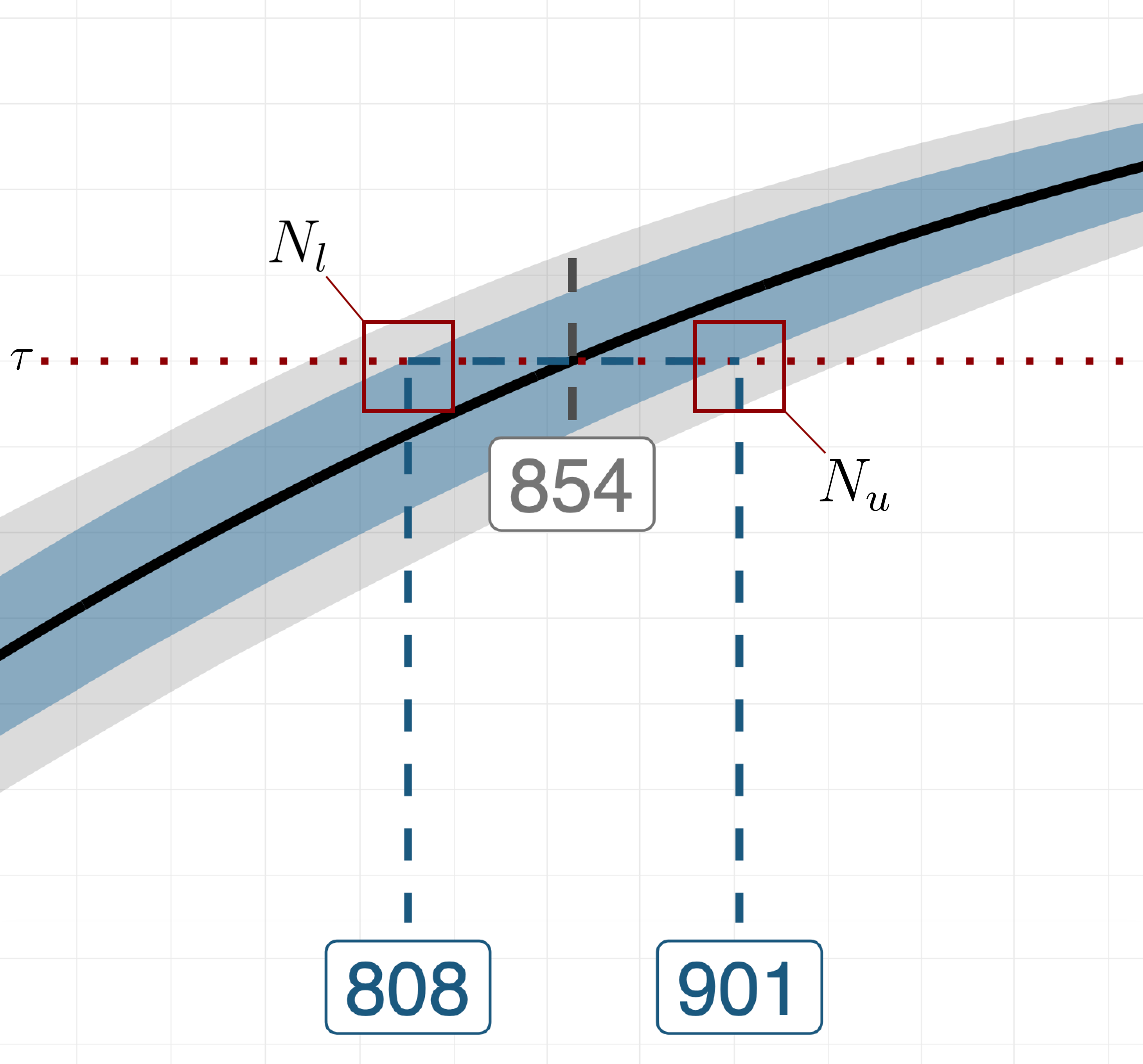
More specifically, we let and be the first sample sizes for which the upper and lower bounds of the CI reach the target value . Deciding whether subsequent method iterations are needed boils down to computing the distance between and and comparing it to a scalar that indicates the tolerance for the uncertainty around the recommended sample size. If , the initial candidate range is updated by setting its lower and upper bounds to and , respectively. Then, we repeat the tree steps of method discussed above, this time concentrating the new set of MC replications on the updated and narrowed-down range of sample sizes, i.e., . The algorithm continues to iterate until either , or a certain number of iterations has been elapsed.
Implementation
As discussed in the introduction of the Tutorial Section, the main function powerly implements the sample size calculation method described above. When using the powerly function to run a sample size analysis, several arguments can be provided as input. For example, the function signature for consists of the following arguments:
# Arguments supported by `powerly`.
powerly(
range_lower,
range_upper,
samples = 30,
replications = 30,
model = "ggm",
...,
model_matrix = NULL,
measure = "sen",
statistic = "power",
measure_value = 0.6,
statistic_value = 0.8,
monotone = TRUE,
increasing = TRUE,
spline_df = NULL,
solver_type = "quadprog",
boots = 10000,
lower_ci = 0.025,
upper_ci = 0.975,
tolerance = 50,
iterations = 10,
cores = NULL,
cluster_type = NULL,
save_memory = FALSE,
verbose = TRUE
)
WARNING
Please note that the function signature of powerly will change (i.e., be simplified) with the release of the version 2.0.0.
These arguments can be grouped in three categories:
- Researcher input.
- Method parameter.
- Miscellaneous.
The table below provides an overview of the mapping between the notation used in Constantin et al. (2023) and the R function arguments. The order of the rows in the table is indicative of the order in which the arguments appear in the method steps.
| Notation | Argument | Category | Description |
|---|---|---|---|
range_lower and range_upper | param | The initial candidate sample size range to search for the optimal sample size. | |
samples | param | The number of sample sizes to select from the candidate sample size range. | |
replications | param | The number of MC replications to perform for each sample size selected from the candidate range. | |
model_matrix | input | The matrix of true parameter values. | |
| - | model | input | The type or family of true model. |
measure | input | The performance measure. | |
measure_value | input | The target value for the performance measure. | |
statistic | input | The statistic (i.e., the definition for power). | |
measure_value | input | The target value for the statistic. | |
| - | monotone | param | Whether to impose monotonicity constraints on the fitted spline. |
| - | increasing | param | Whether the spline is assumed to be monotone non-decreasing or increasing. |
| - | spline_df | param | The degrees of freedom to consider for constructing the basis matrix. |
| - | solver_type | param | The type of solver for estimating the spline coefficients. |
boots | param | The number of bootstrap runs. | |
| - | lower_ci and upper_ci | param | The lower and upper bounds of the CI around the fitted spline. |
tolerance | param | The tolerance for the uncertainty around the recommended sample size. | |
| - | iterations | param | The number of method iterations allowed. |
| - | cores | misc | The number of cores to use for running the algorithm in parallel. |
| - | cluster_type | misc | The type of cluster to create for running the algorithm in parallel. |
| - | save_memory | misc | Whether to save memory by limiting the amount results stored. |
| - | verbose | misc | Whether information should be printed while the method is running. |
TIP
For more information about the data types and default values for the arguments listed above, consult the Reference Section for the powerly function, or the documentation in R by via ?powerly.
Validation
Aside for the method steps discussed earlier, we can also perform a validation check to determine whether the sample size recommendation consistently recovers the desired value for the performance measure according to the statistic of interest. To achieve this, we repeat the MC procedure described in Step 1, with only one selected sample size, namely, the recommendation provided by the method. This results in a vector of replicated performance measures for which compute the statistic of interest. In order to trust the sample size recommendation, the value of the statistic obtained during the validation procedure should be close to the target value specified by the researcher.
TIP
Check out the Reference Section for the validate function for more details on how validate a sample size recommendation.
References
Constantin, M. A., Schuurman, N. K., & Vermunt, J. K. (2023). A General Monte Carlo Method for Sample Size Analysis in the Context of Network Models. Psychological Methods. https://doi.org/10.1037/met0000555
de Leeuw, J. (2017). Computing and Fitting Monotone Splines. http://dx.doi.org/10.13140/RG.2.2.36758.96327
Knuth, D. E. (1992). Two Notes on Notation. The American Mathematical Monthly, 99(5), 403–422. https://doi.org/10.1080/00029890.1992.11995869
Ramsay, J. O. (1988). Monotone Regression Splines in Action. Statistical Science, 3(4), 425–441. https://doi.org/10.1214/ss/1177012761
Wang, W., & Yan, J. (2021). Shape-restricted regression splines with R package splines2. Journal of Data Science, 19(3), 498–517. https://doi.org/10.6339/21-JDS1020